2024-11-28
VETENSKAP: Pseudotecken
Läs om hur hittepå-tecken kan leda till större förståelse av teckenspråk och språklig kommunikation i forskning på universiteten i Linköping, Stockholm och Örebro.
Påhittade tecken kan bidra till förståelsen av teckenspråk.
Om du fick uppgiften att hitta på nya tecken som inte finns i svenskt teckenspråk, hur skulle du gå till väga? Kanske skulle du ta ett existerande tecken och förändra något i tecknet, ungefär som man på talad svenska skulle kunna utgå från ett riktigt ord, till exempel planteringsjord och byta ut t:et mot ett d. Om du nu går till din favoritflorist och frågar om planderingsjord, så kommer hen knappast stå som ett frågetecken och säga, Nej, något sådant har vi inte. Nej, din florist kommer troligen inte ens uppfatta att du bett om något annat än planteringsjord.
Vi människor har nämligen en slags inneboende stavningskontroll som automatiskt justerar sådant som verkar tvetydigt eller oklart i språkliga signaler så att det vi uppfattar är begripliga begrepp, snarare än meningslöst nonsens. Vetenskapligt benämns denna effekt Ganong-effekten och har studerats främst för talat språk, men man kan anta att samma effekt finns i teckenspråk.
Hitta på tecken på svenskt teckenspråkIbland när vi forskar på teckenspråk behöver vi skapa påhittade tecken som inte har någon betydelse. Till exempel kan det vara användbart när vi vill vara säkra på att deltagarna i forskningen inte känner till de tecken de får se i vårt experiment
sedan tidigare. De forskare som hittills har provat att skapa nya betydelselösa, så kallade, pseudotecken för vetenskapliga experiment har gjort som föreslaget ovan. De har utgått från ett befintligt tecken och ändrat något i det, exempelvis handform, läge, riktning eller rörelse, så att tecknets form förändrats. Det är förstås full möjligt att skapa ett nytt tecken på detta sätt.
Risken är dock uppenbar att det nya tecknet framstår som ett felaktigt uttryckt tecken – precis som med planderingsjord – och att den som ser tecknet på grund av Ganong-effekten mentalt byter tillbaka den ändrade handformen till den ursprungliga – man förstår helt enkelt vilket tecken det egentligen borde ha varit. Om detta sker går det inte att anta att man använt betydelselösa pseudotecken i sitt experiment.
I vår studie har vi därför försökt skapa pseudotecken utan att basera dem på existerande tecken. Men hur gör man då något sådant? I alla teckenspråk kombineras olika beståndsdelar för att skapa tecken. De här kombinationerna förekommer olika ofta. Vissa finns med i många tecken, andra finns med i färre. Om vi jämför med talad svenska, och tar ordet plantering som exempel. Låt oss säga att vi pusslar om bokstäverna i ordet, så att vi får lpantering istället. Att ha lp i början av detta ord fungerar inte särskilt bra och går knappt ens att uttala.
Om vi gör samma sak med teckenspråk, det vill säga pusslar ihop olika beståndsdelar på ett sätt som bryter mot hur de brukar förekomma, så kommer vi också få tecken som blir helt felaktiga. Alltså, felaktiga i förhållande till hur tecken brukar se ut i svenskt teckenspråk. De regler som styr villkoren för hur ord och tecken kan sättas samman brukar kallas fonotax. Om man i stället fokuserar på hur ofta olika beståndsdelar i ord eller tecken förekommer ihop får vi något som kallas fonotaktisk sannolikhet. Om man exempelvis har en viss handform, kan man fråga sig vad sannolikheten är att den förekommer i ett visst läge (t.ex. vid huvudet eller sidan av kroppen).
Man kan alltså använda dessa sannolikheter för att avgöra hur pass bra olika beståndsdelar i tecken passar ihop. I vår metod för att skapa pseudotecken har vi först beräknat den fonotaktiska sannolikheten för alla olika kombinationer av teckenbeståndsdelar i svenskt teckenspråk, och sedan har vi slumpat nya kombinationer utifrån dessa sannolikheter. På det här sättet kunde vi skapa pseudotecken som ser ut somtecken i svenskt teckenspråk men som inte har någon betydelse, och inte heller av misstag kan tolkas som ett riktigt tecken. Metoden kräver dock tillgång till ett register med ett stort antal riktiga tecken. Och här har vi haft god nytta av det svenska teckenspråkslexikonet (teckensprakslexikon.su.se) vid Stockholms universitet, som innehåller cirka 20 000 transkriberade tecken.
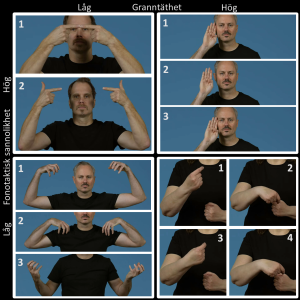
Figuren visar fyra påhittade tecken med hög (övre raden) respektive låg (nedre raden) fonotaktisk sannolikhet och hög (högra kolumnen) respektive låg (vänstra kolumnen) granntäthet. Siffrorna anger bildernas tidsordning.
Betydelsen av fonotaktisk sannolikhet och granntäthet för teckenuppfattning.
Men varför så mycket jobb för att skapa tecken som inte finns? Jo, orsaken är att vi vill undersöka två aspekter som visat sig vara centrala för att uppfatta språk, men som hittills i huvudsak bara har undersökts på talat språk. Dessa aspekter är fonotaktisk sannolikhet – som vi redan varit inne på – och något som kallas granntäthet. I talat språk omvandlas ljuden som kommer in via öronen till elektriska signaler i nervsystemet, vilka hjärnan sedan tolkar för att skapa förståelse.
I processen letar hjärnan i den minnesbank där ordens betydelse lagras – det mentala lexikonet – efter ord som kan matcha den inkommande signalen. I denna process tar hjärnan hjälp av de fonotaktiska sannolikheterna. Om hjärnan exempelvis hör ett b i början av ett ord, är sannolikheten hög att nästa språkljud kan vara ett l. Omvänt, om hjärnan hör ett l först, är det mindre sannolikt att nästa ljud blir ett b. Detta gör det lättare för hjärnan att hitta ord med hög fonotaktisk sannolikhet. Som vi sett är orsaken att vissa ord har hög fonotaktisk sannolikhet just att deras fonotaktiska mönster förekommer ofta i språket.
Att dessa mönster är vanliga i språket innebär att de finns i många ord. Och därför kommer många av dessa ord också likna varandra. Och när ord liknar varandra uppstår en naturlig förväxlingsrisk, vilken gör det svårare för hjärnan att hitta rätt. Vi säger att ord som liknar många andra ord har hög granntäthet, dvs. har många ordgrannar. I bearbetningen av talat språk finns det här alltså två motverkande processer. Hög fonotaktisk sannolikhet underlättar ordidentifiering, medan hög granntäthet gör det svårare att skilja mellan liknande ord. Nu är vi intresserade av att ta reda på hur det ser ut i teckenspråk.
Fungerar det mentala lexikonet på samma sätt på teckenspråk som på talat språk? För att undersöka om fonotaktisk sannolikhet och granntäthet påverkar teckenuppfattning använder vi oss av en uppgift som vi kallar lexikalt beslutstest. I detta test visar vi ett tecken inspelat på video för deltagarna. Tecknet kan antingen vara ett riktigt tecken, som vi antar finns lagrat i testpersonens mentala lexikon, eller ett nyskapat pseudotecken som testpersonen inte sett förut. Uppgiften går ut på att avgöra så snabbt och korrekt som möjligt om tecknet som visas är ett riktigt tecken – något som förutsätter att testpersonen hittat det i sitt mentala lexikon. Om riktiga tecken med hög fonotaktisk sannolikhet identifieras snabbare än tecken med låg fonotaktisk sannolikhet, och på samma sätt, om teckens granntäthet gör dem svårare att skilja från pseudotecknen, tyder det på att liknande processer för fonotaktisk sannolikhet och granntäthet skulle finnas i teckenspråk.
En av utmaningarna i vår studie har varit att beräkna fonotaktisk sannolikhet och granntäthet för teckenspråk. Detta visade sig vara betydligt mer komplicerat än för talat språk. Ett ord i talat språk består av en enda serie av språkljud – ett ljud i taget. När man undersöker hur många grannar ett ord har, kan man enkelt räkna antalet ord som kan bildas genom att byta ut, lägga till eller ta bort ett språkljud i den serien, och den fonotaktiska sannolikheten kan beräknas som sannolikheten för språkljudsföljden i ordet.
I teckenspråk har vi både samtidiga och seriella beståndsdelar att ta hänsyn till. Med andra ord sker det många saker samtidigt i ett tecken, vilka alla också ofta förändras under tecknets utförande – en parallell kombination av beståndsdelar som förändras till nya kombinationer. Enkelt uttryckt är det många fler aspekter att väga in i beräkningarna. Som jämförelse har svenskan ett ganska begränsat antal språkljud – omkring 27 fonem – som går att kombinera för att skapa ord. I svenskt teckenspråk däremot är kombinationsmöjligheterna mycket större: vi räknar med 41 olika handformer, 34 olika lägen, olika sätt att vinkla, och rikta händerna och dessutom har vi två händer som kan utföra olika rörelser samtidigt.
Denna stora skillnad i hur talade språk och teckenspråk är uppbyggda ger oss anledning att misstänka att det mentala lexikonet skiljer sig mellan språken. Det kan därmed finnas nya aspekter av språklig kommunikation att lära från denna teckenspråksstudie. Med våra nya pseudotecken samt beräkningar av fonotaktisk sannolikhet och teckengrannar är vi nu i en god position att kunna besvara denna fråga.
Författare:
Erik Witte, Institutionen för hälsovetenskaper, Örebro universitet
Krister Schönström och Thomas Björkstrand, Institutionen för lingvistik, Stockholms universitet
Henrik Danielsson och Emil Holmer, Institutionen för beteendevetenskap och lärande (IBL), Linköpings universitet)
Dela artikeln via e-post.