2020-05-04
Att utforska tecken eller meningar
Nikolaus Riemer Kankkonen, forskningsassistent, ger här en teckenspråksversion av professor Johanna Meschs artikel.
Svenskt teckenspråkslexikon lanserades online av avdelningen för teckenspråk vid Stockholms universitet redan 2008, vilket är tidigt internationellt sett. Nu har avdelningen lanserat ett nytt korpusverktyg som är tillgängligt för allmänheten: Svensk teckenspråkskorpus (STS-korpus). Här ger Johanna Mesch, professor i teckenspråk, en kortare beskrivning av verktyget.
I TV och sociala medier förekommer tecknet CORONA med uttalsvarianter. Det finns många mer eller mindre kända tecken som man vill veta mer om och fråga andra, till exempel i Teckenspråkslexikonets Facebookgrupp, hur de tecknar ett visst tecken och vilken teckenvariant de brukar använda.
Precis som för många andra språk finns det språkresurser för svenskt teckenspråk tillgängliga för allmänheten. Språkresurser är en allmän term för språkrelaterad teknik och datamängder som har utvecklats för att ge stöd till språkundervisning, forskning, självstudier och t.ex. sökning efter ett visst ord/tecken. Resurserna kan bestå av maskinläsbara textdatabaser, lexikon, och digitala verktyg för att interagera med dem.
Svenskt teckenspråkslexikon lanserades online redan 2008, vilket är tidigt i ett internationellt perspektiv. Nu har det kommit flera verktyg för svensk teckenspråkskorpus. En korpus är inom språkvetenskapen en större samling texter som kan bestå av skrivet, talat eller tecknat språk. Talade och tecknade texter är oftast transkriberade och texterna i en korpus är ofta annoterade (uppmärkta), till exempel med ordens ordklass eller satsdelsfunktion.
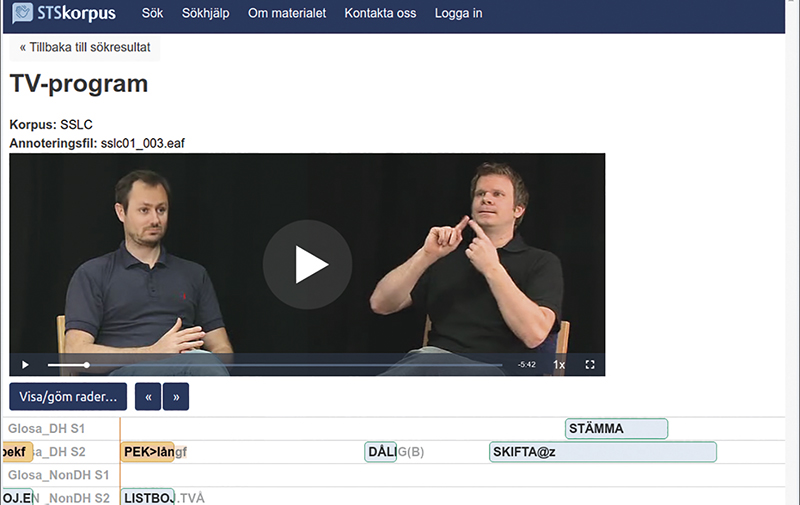
Här beskriver jag kort vårt nya korpusverktyg, STS-korpus. Efter 17 års utvecklingsarbete med teckenspråkskorpusar är det dags att utforska teckenspråk med data från flera korpusar på ett bekvämt sätt genom ett webbaserat korpusverktyg, STS-korpus (STS står för svenskt teckenspråk).
Först vill jag beskriva lite av bakgrunden, hur korpusarna blev till. För korpusarbete behövs videoinspelade teckenspråkstexter och programmet ELAN som är ett multimodalt annoteringsverktyg, utvecklat vid forskningsinstitutet MPI i Nijmegen, Nederländerna.
I ELAN kan olika typer av annoteringar göras på olika rader, och annoteringarna länkas till videosekvenser i realtid. Det är ett komplext program för annotering, sökning och visning av (bl.a.) teckenspråkskorpusar. Annotering betyder uppmärkning, dvs. att markera en kortare eller längre sekvens i videon och skriva in glosa, översättning, grammatisk information eller annan kommentar.
Befintliga korpusar
Den första korpusen, ECHO-korpusen, skapades 2003–2004 inom ett samarbetsprojekt mellan Radbound University i Nijmegen, City University in London och Stockholms universitet. De ingående texterna är främst fabelberättelser på svenskt, nederländskt och brittiskt teckenspråk. Två döva aktörer från Sverige har varit med i denna korpus.
Senare, tack vare finansiering från Riksbankens Jubileumsfond 2009-2011, kom ett större korpusprojekt igång. Då samlades korpusdata in från 42 personer i olika åldrar från hela landet. Totalt genererade inspelningarna 24 timmar redigerade filmer. Denna omfattande korpus heter SSLC.
Efter tio års annoteringsarbete är cirka 80 % av korpusen annoterad med teckenglosor och en lite mindre del med svensk översättning. Vi har också samlingar av tecknade texter av dövblinda och hörande andraspråksinlärare.
För alla teckenspråkskorpusar går annoteringsarbetet långsamt eftersom det sker manuellt. Vi har haft många tillfälliga projektanställda som arbetat med annoteringar, vilket vi är tacksamma för. Parallellt har vi ständigt utvecklat och uppdaterat annoteringskonventioner för teckenglosor och grammatisk information, hur man ska döpa t.ex. SPRINGA ’springa’ och dess olika teckenvarianter till olika glosbenämningar (ID-glosa) och vilka grammatisk information som ska prioriteras.
Teckenglosa kan ses som tecknets/betydelsens namn, och anges med ett svenskt ord med motsvarande betydelse, i grundform, skrivet med versaler – det betyder dock inte alltid att tecknet helt motsvarar det svenska ordet.
Syfte med korpusar
När du vill leta efter något uttryck kan du göra en sökning i flera texter samtidigt och få se uttrycket i olika kontexter. Korpusar är stora databaser med autentiska (naturligt producerade) teckenspråkstexter där man kan göra sökningar och hitta svar på forsknings- eller språkbruksfrågor. Framförallt är det teckenspråksforskare, lexikonarbetare och språkvårdare som har använt sig av korpusar – men idag finns det en del korpusar tillgängliga online.
Teckenspråkskorpusar kan användas för att ta reda på sådant som kan vara svårt att hitta information om i teckenspråkslexikonet, exempelvis teckenvarianter, t.ex. former av ANNAN ’annan’, i vilka sammanhang ett visst tecken används, eller vilken grammatisk form som är vanligast. På så sätt ger den språkvetenskapligt annoterade korpusen information på högre nivå än bara enskilda tecken.
STS-korpus för undervisning och allmänheten
STS-korpus startades i början av mars 2020. Det är ett gränssnitt vilket betyder att du kan gå till https://teckensprakskorpus.su.se utan att vara teknisk expertis, installera någonting eller ha tillgängligt hårddiskutrymme eller inloggning i klassrumsdator för att ladda ner programvara. STS-korpus är skapat för att vara ett enkelt och användarvänligt korpusverktyg.
I STS-korpus kan du ”bläddra” igenom olika teckenuttryck och presentera dem för studenter. Det är viktigt att nämna att teckenspråkskorpusarna fortfarande är små och att alla forsknings- eller språkbruksfrågor inte kan besvaras, men i många fall kan man få en fingervisning hur ett tecken eller en teckenspråksmening ser ut. Skriftkorpusar används ofta i andraspråksutbildning. Nu är det möjligt att använda STS-korpus som verktyg i andraspråksundervisning i ämnet teckenspråk, och lärare kan bekvämt utnyttja det i sin undervisning.
Sökresultat
Användaren kan gå in i STS-korpus och skriva någon glosa, t.ex. BADA* (jokertecken * står för noll till flera ”valfria” bokstäver). Det ger en lista över alla tecken med betydelse BADA hos olika tecknare och i olika texter, inklusive sammansatta tecken som översättningslån, t.ex. BADA^RUM ’badrum’ eller BADA^KALSONG ’badkalsong’. Sökprefix kan begränsa sökningen till specifika annoteringsrader, filer eller korpusnamn.
Uppspelningshastigheten kan justeras från 1x till 0.25x. Annoteringar och video är alltid synkroniserade så att användaren kan navigera genom att bläddra i annoteringar eller genom att hoppa till en annan videoruta med hjälp av muspekaren.
STS-korpus har olika åtkomstnivåer för forskare, lärare och studenter som reglerar hur mycket innehåll de får ta del av. För allmänheten är ett begränsat antal filer tillgängliga och rader synliga. Efter Dataskyddsförordningens införande har vi anonymiserat egennamn i annoteringarna även om persontecken framförs i videon.
Programmering och design av STS-korpus har gjorts av Patrick Hansson och Zrajm med syftet att skapa ett lättnavigerat korpusverktyg som är anpassat för teckenspråkskorpusar. Det har möjliggjorts av ett samarbete med teckenspråkslexikonverksamheten och andra forskare vid Institutionen för lingvistik. Dock behövs det en del justeringar och förbättringar samt utökad teckenspråksdata.
Vi kommer att utveckla språkvetenskaplig information som uppmärkning av ordklasser, satsgränser, munrörelser och andra markörer som är speciella för teckenspråk, såsom osynliga referenter. I framtiden kan det också bli möjligt för lärare att ladda upp eget annoterat teckenspråksmaterial för undervisning.
Avslutning
Det är fortfarande ont om läromedel om teckenspråksgrammatik, även om svenskt teckenspråkslexikon finns tillgängligt online och i appar. STS-korpus erbjuder ett sätt att direkt kolla upp saker som studenter frågar om, tillsammans med dem eller på egen hand.
Vi har ett visst samarbete med andra forskningsenheter genom Swe-Clarin som är en nationell e-infrastruktur till stöd för forskning baserad på språkliga data. Vi har också långtgående samarbete med bland andra nederländska, brittiska, tyska, japanska, sydafrikanska, brasilianska och amerikanska forskare med korpusar på sina respektive teckenspråk.
Under 2020-talet kommer vi att ha ett utökat nätverk av nordiska teckenspråkiga forskare som arbetar med multimodala teckenspråkskorpusar från ett kognitivt-funktionellt språkligt perspektiv. Syftet är att utveckla korpusmetoder som bidrar till fördjupad förståelse av teckenspråken och av mänskligt språk mer generellt.

JOHANNA MESCH
Professor i teckenspråk
Institutionen för lingvistik, Stockholms universitet
Dela artikeln via e-post.